Doppelt annotierte Korpora (DAK)
„Natur & Staat“ und Reichstagsprotokolle als Ressourcen für die innovative automatische Metaphernanalyse
Laufzeit: 1.2020 – 7.2021
---
Projektteam:
Dr. Steffen Eger | FB 20, Informatik – AIPHES
Prof. Dr. Petra Gehring | FB 2, Philosophie der Technowissenschaften
---
Projektbeschreibung:
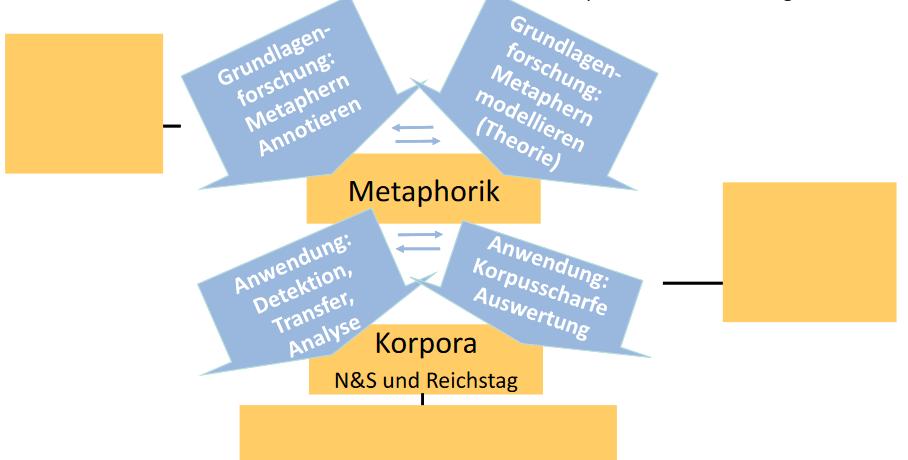
Metaphern zu modellieren, zu identifizieren und hinreichend eindeutig zu verstehen stellt sowohl im informatischen Zusammenhang als auch für die Geisteswissenschaften (wo Metaphern schon seit der Antike als offenes Problem diskutiert werden) eine große Herausforderung dar. Denn Metaphern sind irreguläre Phänomene, und es existiert eine Vielzahl verschiedenster Theorien dazu, wie Metaphern funktionieren.
Infolgedessen stehen der digital arbeitenden Forschung auch nur wenige Metaphern-Datensätze zur Verfügung, insbesondere in anderen als der englischen Sprache. Solche Datensätze werden jedoch benötigt, und zwar sowohl in der Informatik, als Trainingsgrundlage für Verfahren zur Metapherndetektion mittels Maschinellem Lernen (was vertieftes Textverständnis auf automatisierter Grundlage ermöglicht), als auch in der hermeneutischen Forschung, wo sich die Geisteswissenschaften digitaler Verfahren bedienen, um die Typik und das Vorkommen von Metaphern in historisch variierenden Textgattungen zu untersuchen. Kontraste verschiedener Metaphernkonzepte und Wandel von Metaphorik sind dabei von besonderem Interesse.
Vor diesem Hintergrund trägt DAK dazu bei, gleich zwei Lücken zu schließen: Es schafft (1.) große, annotierte Datensätze aus forschungsrelevanten deutschsprachigen Korpora, und es trainiert (2.) mit deren Hilfe Modelle des Maschinellen Lernens, um diese in die Lage zu versetzen, Metaphern in Texten zu identifizieren. Um Metaphern-Konzepte und methodologische Herausforderungen miteinander zu kontrastieren wurden plangemäß zwei Annotationsstrategien verwendet: einmal wurde eine metapherhistorische, text- und lesepragmatische Metapherntheorie (Danneberg et al.), einmal eine klassische (Lakoff/Johnson – als „Standardmodell“) genutzt. Beide wurden zur Detektion von Metaphorik in mehreren historischen Datensätzen erprobt, die Entwicklungen von politischen Diskursen auf dem Weg zum ersten und zweiten Weltkrieg betreffen.
Im Ergebnis haben die Antragsteller zunächst auf über 57.000 Zeilen OCR-Korrekturen in historischen Korpora vorgenommen (über etliche Bücher sowie Protokolle historischer Parlamentsdebatten hinweg). So war eine automatisierte OCR-Fehlerreduktion um über 30% möglich. Daraufhin wurden mehrere hundert Metaphern in dem heterogenen, historischen Quellenmaterial identifiziert – und zwar basierend auf jenen zwei verschiedenen Theorien. Auf den so entstandenen, annotierten Datensätzen haben wir erste computergestützte Metaphernmodelle zur automatischen Identifikation trainiert. In den Blick gerückt sind dabei u.a. die Annotationskriterien und Probleme der Annotierbarkeit (des Annotator Agreement), die bei beiden Metaphernmodellen zunächst bestanden haben.
